Server Message Aggregation
Ingress Fan-In Architecture
Full message data aggregation, processing and storage is a common need for PubNub customers. There are a few different ways to approach this, but they all share the same core concepts. When developing an application that uses PubNub to fulfill many use cases, often the growth of the use of channels also grows with it. Later in the process, how to aggregate this data across so many channels becomes a new concern that may not have been an initial requirement.
The Un-Ideal Scenario
Naturally, when one thinks of how to aggregate all that data on backend servers after the application was already developed, simply adding the server as a subscriber is the first approach. It’s natural because we first think of how our users interact with each other, designing the application data streams to support user interactions and realtime activities, and think of the server aggregation as a secondary concern.
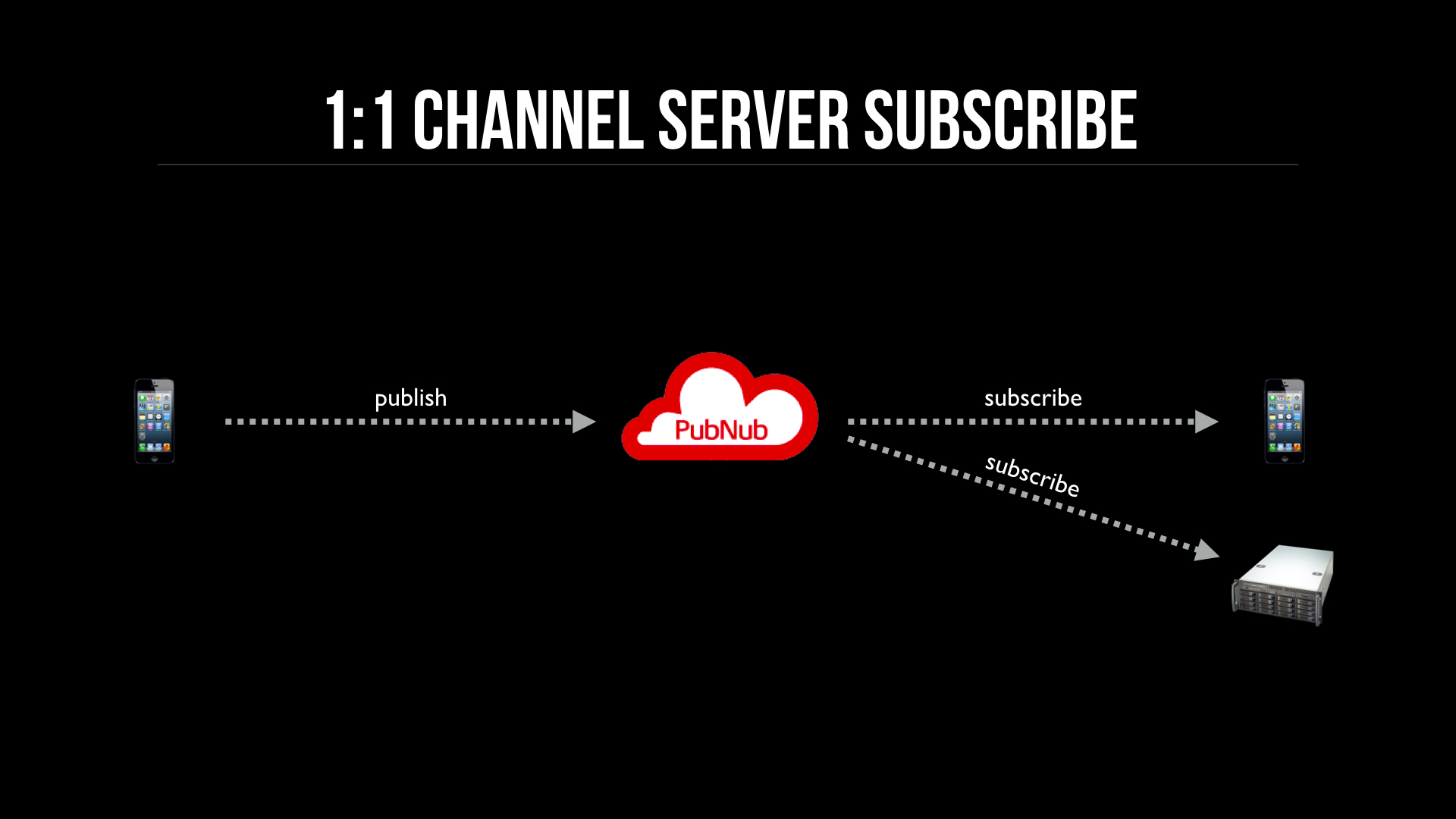
This visualization shows a publisher and subscriber on a channel, and the server subscribing to the same channel to also receive published messages. The main problem with this scenario is what happens when you scale up, as can be seen in the next visualization.
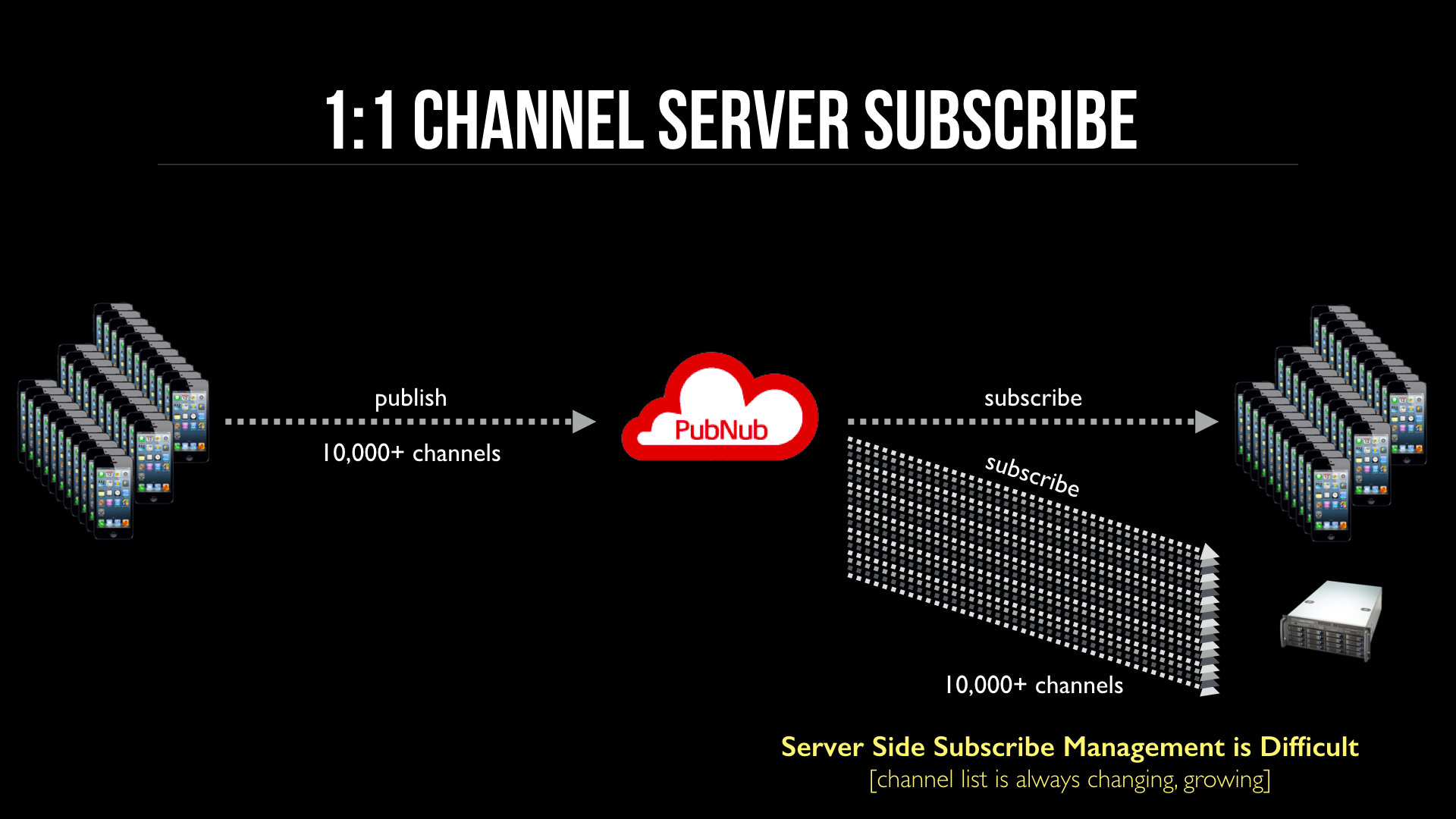
This design has many problems and challenges:
- Channel List grows indefinitely
- Every new channel created has to have corresponding server subscribe, on-time without race conditions
- Cannot predictably scale server load
- Message distribution is uneven
- Horizontal scaling very complicated
High Throughput & Scalable##
The main challenges of adding server subscriber to every used channel is Management and Predictable Throughput. A better approach is to replace an indefinite number of channels to a finite set of channels that are dedicated for inbound messages. By dedicating channels to ingress/inbound traffic, you can control throughput, horizontal scaling, and reduce processing hotspots and uneven distribution.
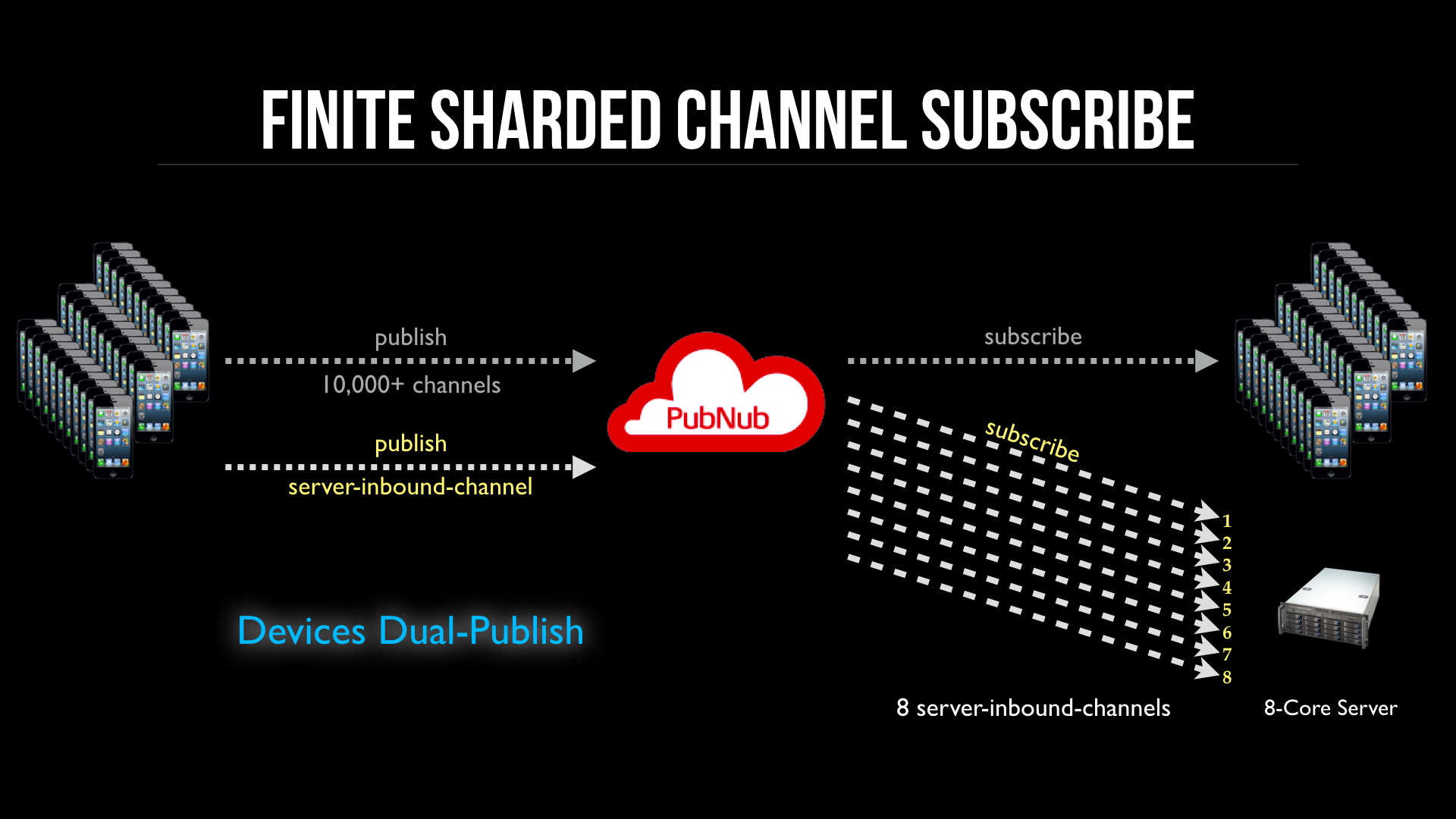
Server Side
In this visualization you see there are 8 dedicated “Server Inbound” channels, one for each CPU core. They also have a consistent channel naming scheme, like “server-inbound-1, server-inbound-2”, etc. Each subcriber process only subscribes to one channel, and there are 8 processes running. This allows CPU core alignment to take place, since the OS will decide the process-core assignment. This is the most optimal design for I/O because each process requests I/O access from the CPU, and having more processes than CPU cores only slows down I/O by competing for I/O time from the CPU core.
Client Apps
Client apps will dual publish to both the normal channel and one of the server-inbound shards. Using a consistent hash you can shard the publishes evenly across shards and many client apps.
Why Sharding?
When you are receiving messages on a process, and you have multiple processes, you want consistent growth and have predictable load for each process. If all the messages end up on one process, that process will get overloaded. There are some examples in the past where data sharding wasn’t done properly within distributed databases that illustrate this problem, where a particular database shard was receiving 80% of the traffic and would crash.
A fairly standard sharding scheme, used in Memcache/Membase/Couchbase and many other places, is using a CRC32 hash on a unique value which results in a number that you modulus with the shard count. This creates a very evenly distributed load. Another options is using FNV-1a hash to do a similar thing.
Here is an example to see how sharding publishes from the client looks like:

Using Blocks to Fan-In
I will be adding some more content to this post over time, the above covers the basics. Some of the content I will add includes:
- Horizontal Scaling of Server Side Ingress
- How Blocks will help Ingress patterns
- Middleman Alternatives & Pro/Cons
- PubNub’s Streaming API